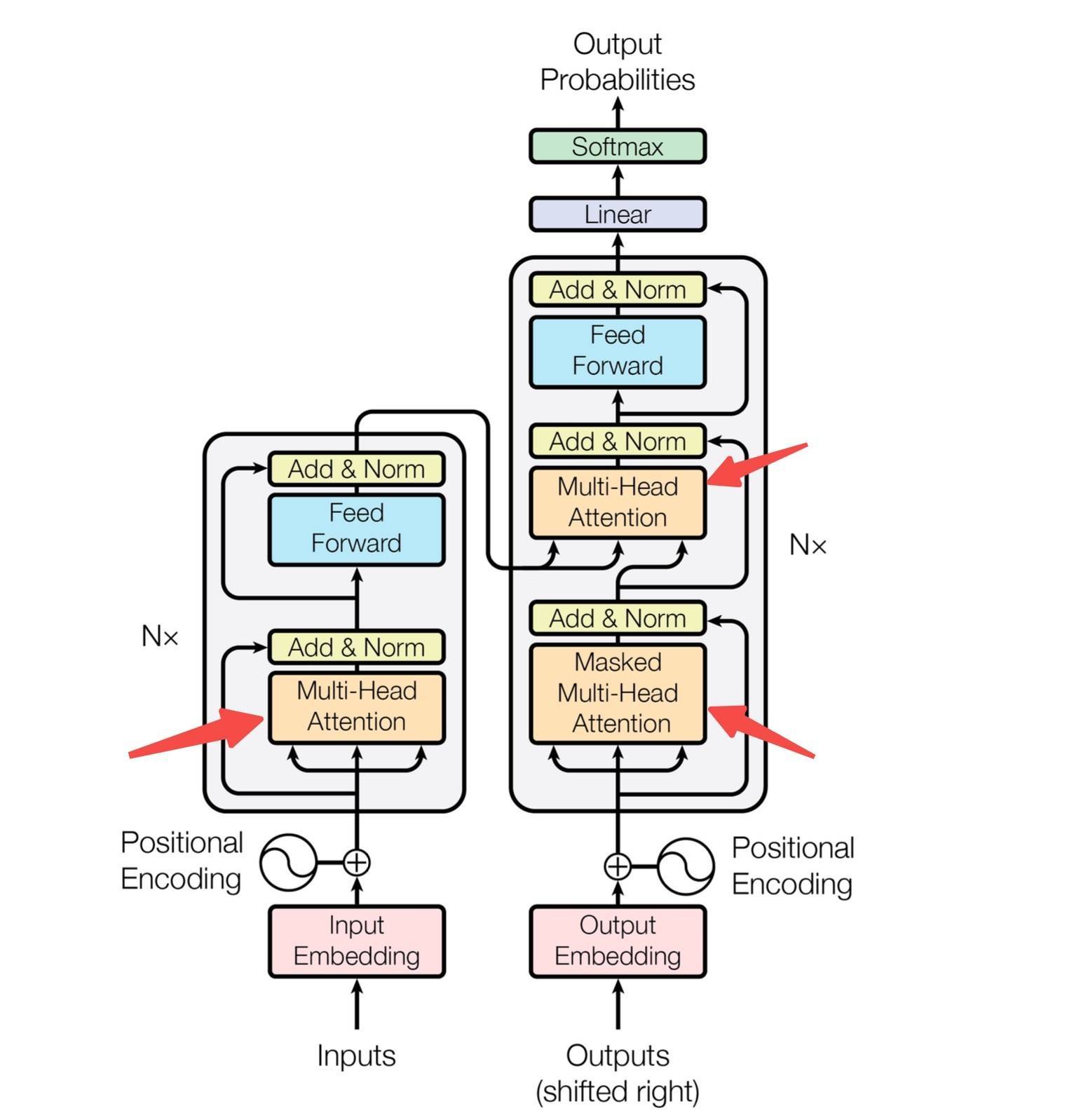
 研究团队把这种思路称为“锥形语言模型”(TLMs)。他们尝试了线性、余弦、S形三种递减曲线,结果余弦曲线一骑绝尘——前段宽度1.5倍、后段0.5倍时,困惑度狂降1.84点。这相当于在不增加计算量的情况下,让模型“脑容量”利用率提升12%。更神奇的是,这套方案直接套用到门控注意力、Hope-attention等不同架构上,所有模型在常识推理和语言预测任务中集体进步,连处理长文本的能力都没打折。比如在“大海捞针”测试中,模型依然能准确找出埋藏在十万字中的关键信息。 为什么前段层更“吃”参数?科学家用GPT-2做了个实验:越往模型深层走,新生成的内容和已有信息越相似。就像写作文时,开头需要天马行空的创意(需要大容量),结尾只需润色收尾(小容量就够了)。这项研究戳破了行业长期误区——参数不该平均分配,而要像浇花一样精准滴灌到最需要的地方。现在各大实验室都在悄悄调整模型“身材”,说不定你手机里的AI助手,正悄悄变着“聪明形”呢。下次当你问“明天天气如何”时,背后可能正有个“锥形大脑”在高效运转,用更少的力气给出更准的答案。
研究团队把这种思路称为“锥形语言模型”(TLMs)。他们尝试了线性、余弦、S形三种递减曲线,结果余弦曲线一骑绝尘——前段宽度1.5倍、后段0.5倍时,困惑度狂降1.84点。这相当于在不增加计算量的情况下,让模型“脑容量”利用率提升12%。更神奇的是,这套方案直接套用到门控注意力、Hope-attention等不同架构上,所有模型在常识推理和语言预测任务中集体进步,连处理长文本的能力都没打折。比如在“大海捞针”测试中,模型依然能准确找出埋藏在十万字中的关键信息。 为什么前段层更“吃”参数?科学家用GPT-2做了个实验:越往模型深层走,新生成的内容和已有信息越相似。就像写作文时,开头需要天马行空的创意(需要大容量),结尾只需润色收尾(小容量就够了)。这项研究戳破了行业长期误区——参数不该平均分配,而要像浇花一样精准滴灌到最需要的地方。现在各大实验室都在悄悄调整模型“身材”,说不定你手机里的AI助手,正悄悄变着“聪明形”呢。下次当你问“明天天气如何”时,背后可能正有个“锥形大脑”在高效运转,用更少的力气给出更准的答案。
盛多网提示:文章来自网络,不代表本站观点。